

《Linux命令行与shell脚本编程大全》第二十章 正则表达式
原创-
 2023-12-21 15:18:42
2023-12-21 15:18:42
-
 1734
1734
本篇目录
20.1 什么是正则表达式
20.1.1 定义
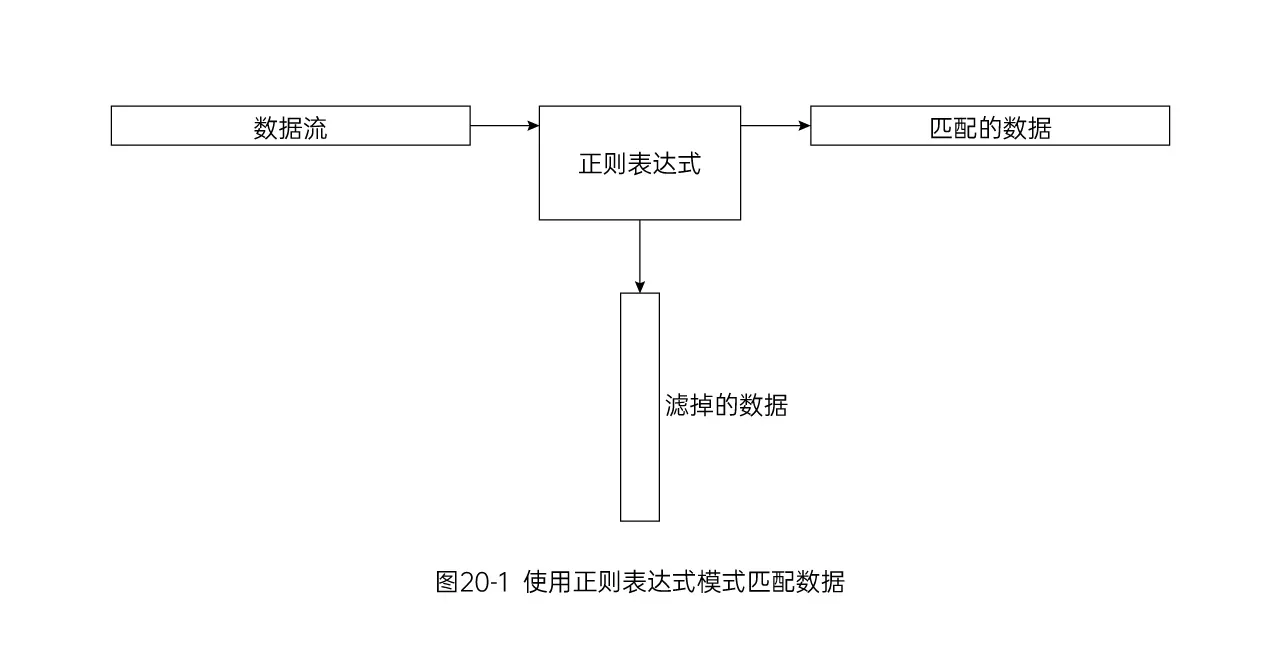
正则表达式是你所定义的模式模板,Linux工具可以用它来过滤文本。比如sed编辑器或gawk程序在处理数据时使用正则表达式对数据进行模式匹配。如果数据匹配模式,会被接受并进一步处理;不匹配模式,就会被滤掉。
20.1.2 正则表达式的类型
正则表达式是通过正则表达式引擎(regular expression engine)实现的。
Linux中,有两种流行的正则表达式引擎:
POSIX基础正则表达式(basic regular expression,BRE)引擎
POSIX扩展正则表达式(extended regular expression,ERE)引擎
sed编辑器只符合了BRE引擎规范的子集
gawk程序用ERE引擎来处理它的正则表达式模式
20.2 定义 BRE 模式
20.2.1 纯文本
正则表达式并不关心模式在数据流中的位置。它也不关心模式出现了多少
次。一旦正则表达式匹配了文本字符串中任意位置上的模式,它就会将该字符串传回Linux工具。
数据流的位置、出现的次数不影响正则表达式匹配文本字符串。
正则表达式模式都区分大小写
正则表达式中使用空格和数字,也可以匹配多个连续空格
20.2.2 特殊字符
正则表达式识别的特殊字符包括
.*[]^${}\+?|()
要用某个特殊字符作为文本字符,就必须转义
反斜线是转义字符,加在特殊字符前。
由于反斜线是特殊字符,如果要在正则表达式模式中使用它,必须对其转义,这样就会有两个反斜线。
正斜线不是特殊字符,但是不转义会有错误,也需要转义
20.2.3 锚字符
脱字符^
1. 锁定在行首
脱字符(^)定义从数据流中文本行的行首开始的模式
脱字符出现在正则表达式模式的尾部,sed编辑器会将它当作普通字符来匹配。
2. 锁定在行尾
美元符($)定义了行尾锚点,将这个特殊字符放在文本模式之后来指明数据行必须以该文本模式结尾。
3. 组合锚点
同一行中将行首锚点和行尾锚点组合在一起使用。
将两个锚点直接组合在一起,之间不加任何文本,这样过滤出数据流中的空白行。这是从文档中删除空白行的有效方法。
20.2.4 点号字符
特殊字符点号用来匹配除换行符之外的任意单个字符。必须匹配一个字符,如果在点号字符的位置没有字符,那么模式就不成立。
. XX,点号位置必须有字符,包括空格
20.2.5 字符组
使用方括号来定义一个字符组。方括号中包含所有你希望出现在该字符组中的字符。
[wl]an
在不太确定某个字符的大小写时,字符组会非常有用。
[Yy]es
可以在单个表达式中用多个字符组。
字符组不必只含有字母,也可以在其中使用数字
如果要确保只匹配五位数,就必须指明它们就在行首和行尾
字符组的一个极其常见的用法是解析拼错的单词
20.2.6 排除型字符组
寻找组中没有的字符,只要在字符组的开头加个脱字符,
[^cm]atain将含有c或m的排除了
20.2.7 区间
只需要指定区间的第一个字符、单破折线以及区间的最后一个字符就行了
^[0-9][0-9][0-9][0-9][0-9]$
也适用于字母
[c-h]at
还可以在单个字符组指定多个不连续的区间
[a-ch-m]at
20.2.8 特殊的字符组
BRE特殊字符组
|
组 |
描述 |
|
[[:alpha:]] |
匹配任意字母字符,不管是大写还是小写 |
|
[[:alnum:]] |
匹配任意字母数字字符0~9、A~Z或a~z |
|
[[:blank:]] |
匹配空格或制表符 |
|
[[:digit:]] |
匹配0~9之间的数字 |
|
[[:lower:]] |
匹配小写字母字符a~z |
|
[[:upper:]] |
匹配任意大写字母字符A~Z |
|
[[:print:]] |
匹配任意可打印字符 |
|
[[:punct:]] |
匹配标点符号 |
|
[[:space:]] |
匹配任意空白字符:空格、制表符、NL、FF、VT和CR |
可以用[[:digit:]]来代替区间[0-9]
20.2.9 星号
/colou*r/p
u出现0次或多次都可以匹配。如果你知道一个单词经常被拼错,你可以用星号来允许这种错误。
将点号特殊字符和星号特殊字符组合起来。能够匹配任意数量的任意字符。/regular.*expression/p
星号还能用在字符组上。它允许指定可能在文本中出现多次的字符组或字符区间。
/b[ae]*t/p
只要a和e字符以任何组合形式出现在b和t字符之间(就算完全不出现也行),模式就能够匹配。如果出现了字符组之外的字符,该模式匹配就会不成立。
20.3 扩展正则表达式
ERE模式包括了一些额外符号。gawk程序能够识别ERE模式,但sed编辑器不能。gawk程序可以使用大多数扩展正则表达式模式符号,能提供一些额外过滤功能,sed编辑器不具备。
gawk程序在处理数据流时比较慢。
20.3.1 问号
问号表明前面的字符可以出现0次或1次,不会匹配多次出现的字符。
可以将问号和字符组一起使用。如果字符组中的字符出现了0次或1次,模式匹配就成立。但如果两个字符都出现了,或者其中一个字符出现了2次,模式匹配就不成立。
20.3.2 加号
加号表明前面的字符可以出现1次或多次,但必须至少出现1次。如果该字符没有出现,那么模式就不会匹配。
加号同样适用于字符组,如果字符组中定义的任一字符出现了,文本就会匹配指定的模式。
20.3.3 使用花括号
ERE中的花括号允许你为可重复的正则表达式指定一个上限,通常称为间隔。
可以用两种格式来指定区间。
m:正则表达式准确出现m次。
m, n:正则表达式至少出现m次,至多n次。
默认情况下,gawk程序不会识别正则表达式间隔。必须指定gawk程序的--re- interval命令行选项才能识别正则表达式间隔。
间隔模式匹配同样适用于字符组。字母a或e在文本模式中只出现1~2次,是指a出现的次数加上e出现的次数,总共1~2次则正则表达式模式匹配;否则,模式匹配失败。
20.3.4 管道符号
管道符号允许你在检查数据流时,用逻辑OR方式指定正则表达式引擎要用的两个或多个模式。如果任何一个模式匹配了数据流文本,文本就通过测试。如果没有模式匹配,则数据流文本匹配失败。
使用管道符号的格式如下:
expr1|expr2|...
正则表达式和管道符号之间不能有空格,否则它们也会被认为是正则表达式模式的一部分。
管道符号两侧的正则表达式可以采用任何正则表达式模式(包括字符组)来定义文本。
20.3.5 表达式分组
用圆括号进将正则表达式模式分组时,该组会被视为一个标准字符。可以像对普通字符一样给该组使用特殊字符。
将分组和管道符号一起使用来创建可能的模式匹配组是很常见的做法。
模式(c|b)a(b|t)会匹配第一组中字母的任意组合以及第二组中字母的任意组合。
20.4 正则表达式实战
20.4.1 目录文件计数
20.4.2 验证电话号码
在美国,电话号码有几种常见的形式:
(123)456-7890
(123) 456-7890
123-456-7890
123.456.7890
gawk程序中使用正则表达式间隔时,必须使用--re-interval命令行选项
可以将电话号码重定向到脚本来处理。
也可以将含有电话号码的整个文件重定向到脚本来过滤掉无效的号码。





完善信息领取项目管理礼包







