读书笔记《Linux命令行与shell脚本编程大全》第22章
原创-
 2023-12-21 15:16:33
2023-12-21 15:16:33
-
 1517
1517
本篇目录
1. 使用变量
gawk编程语言支持两种不同类型的变量:内建变量和自定义变量。
1.1 内建变量
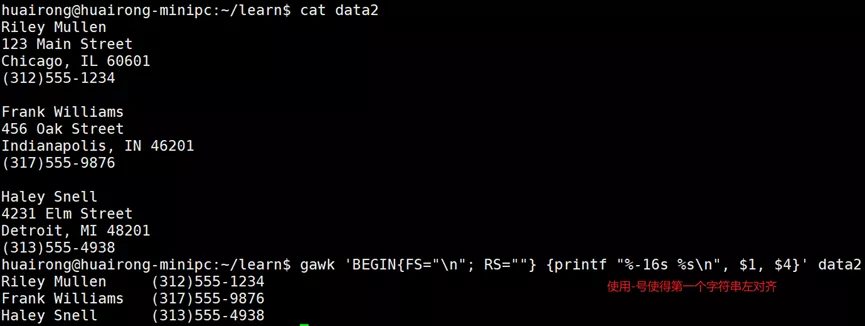
Gawk程序使用内建变量来引用程序数据里的一些特殊功能。(1)字段和记录分隔符变量
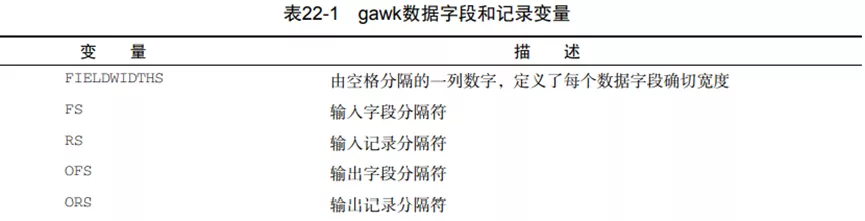
采用字段宽度进行分隔的例子:
只要设置了FIELDWIDTH变量,gawk就会忽略FS变量,并根据提供的字段宽度来计算字段。
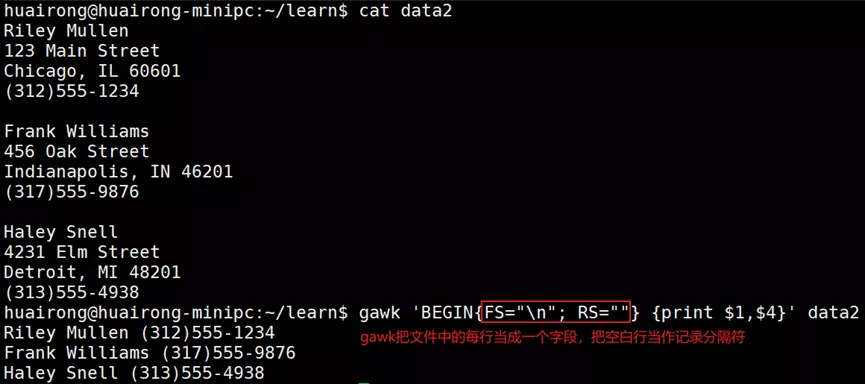
(2)数据变量




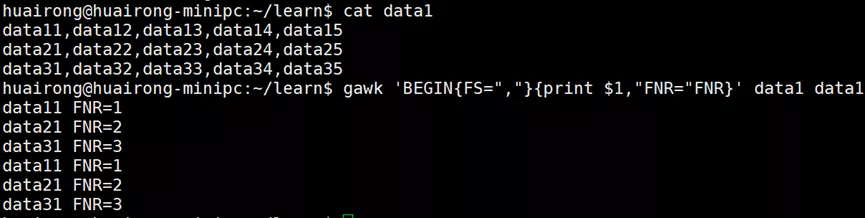
FNR变量的值在gawk处理第二个数据文件时被重置了,而NR变量则在处理第二个数据文件时会继续计数。
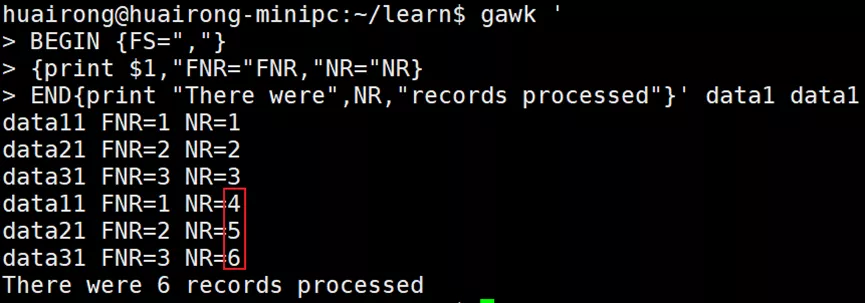
1.2 自定义变量
Gawk自定义变量名支持任意数量的字母、数字、下划线,但不能以数字开头,且变量名区分大小写。(1)在脚本中给变量赋值
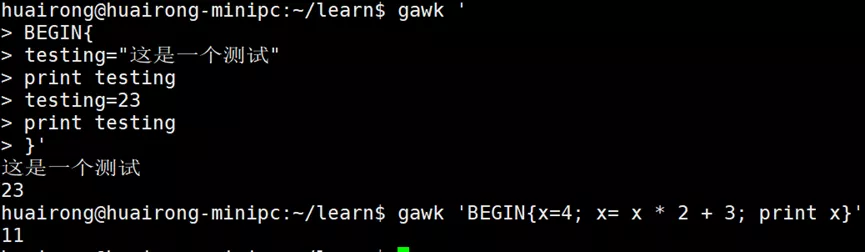
(2)在命令行上给脚本赋值
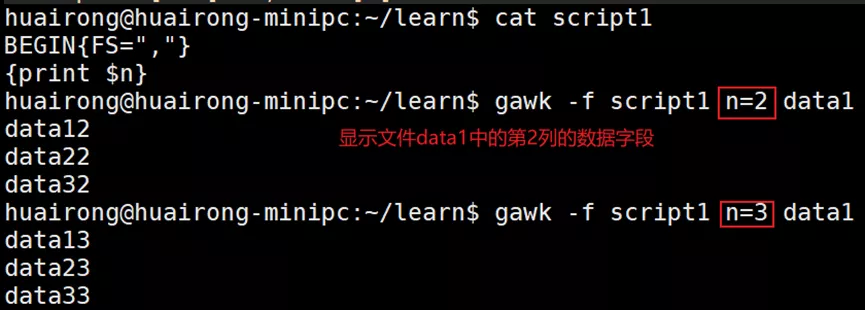
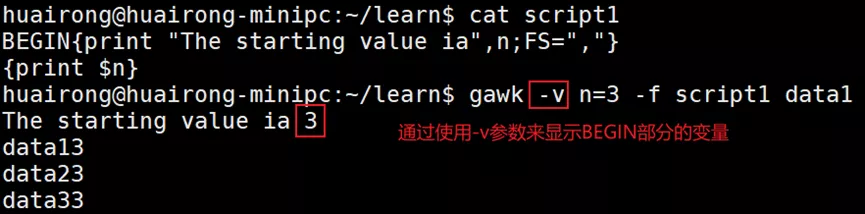
2. 处理数组
2.1 定义数组变量
数组变量赋值的格式:var[index] = element;- Var:变量名;
- index:关联数组的索引值;
- element:数据元素值。
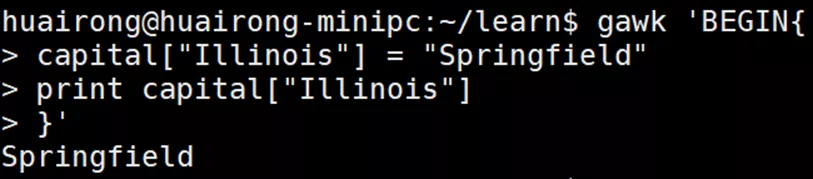
2.2 遍历数组变量
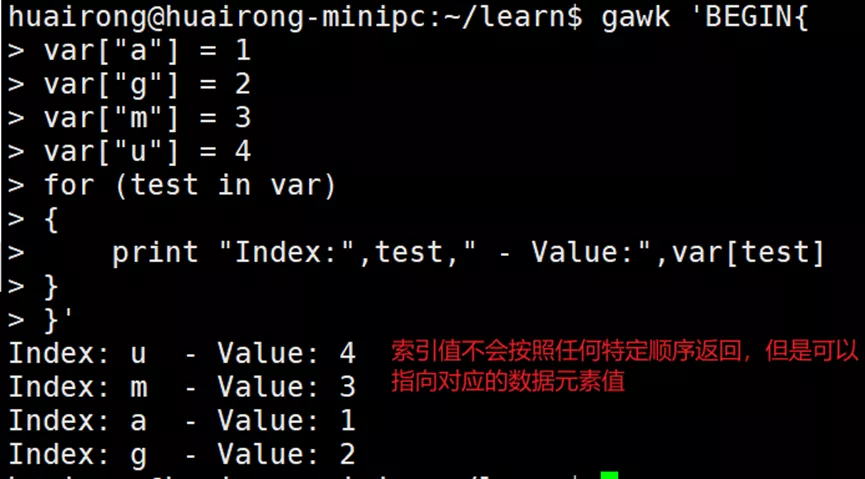
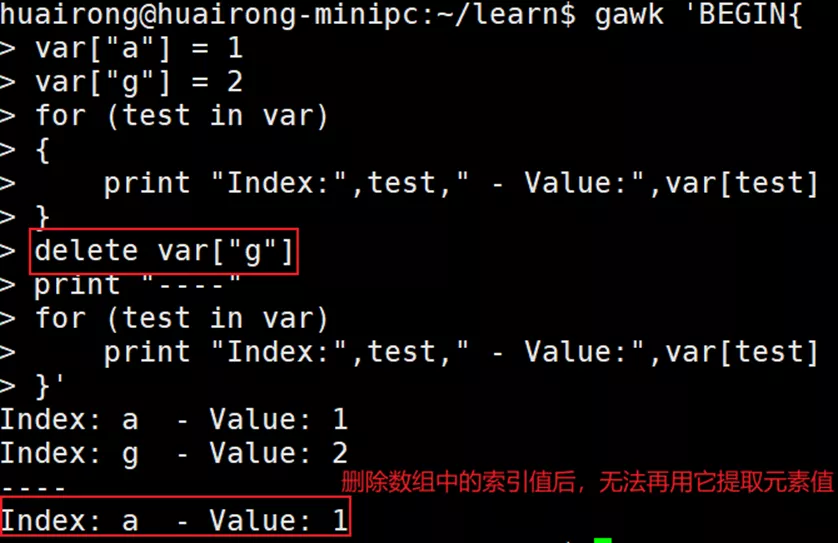
2.3 删除数组变量
delete array[index]
3. 使用模式
正则表达式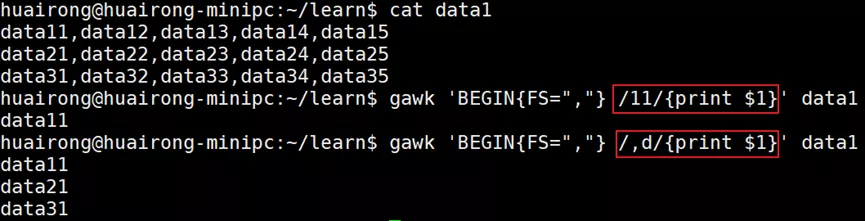
匹配操作符
匹配操作符是波浪线:~


数学表达式
可以使用任何常见的数学比较表达式:等于==、小于等于<=、小于<、大于等于>=、大于>,表达式必须是完全匹配,数据必须和模式严格匹配。

4. 结构化命令
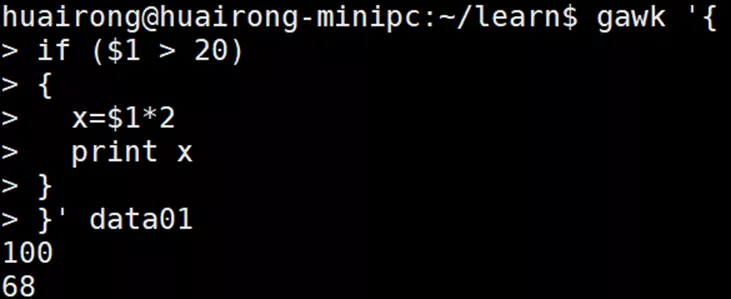
If语句,支持两种格式:- if (condition)
- statement1
- if (condition) statement1
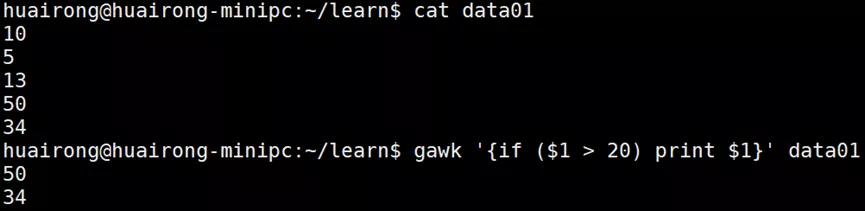

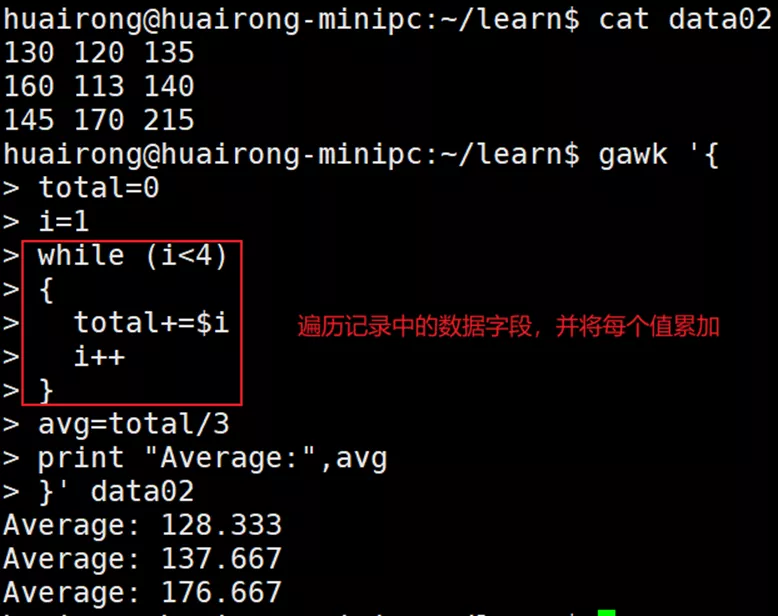
while语句
while (condition){
Statements
}
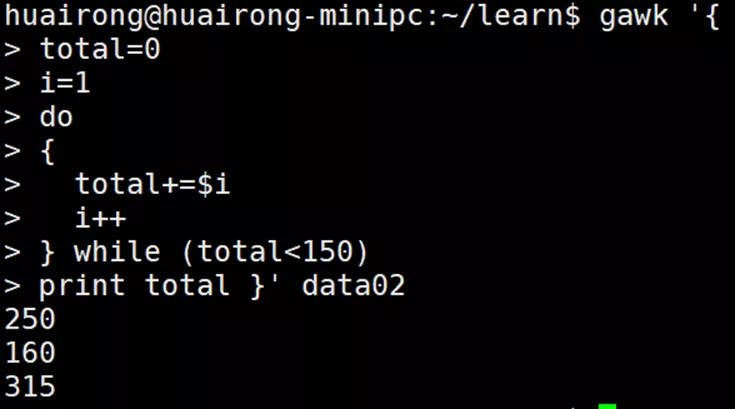
do
{
statements
} while (condition)
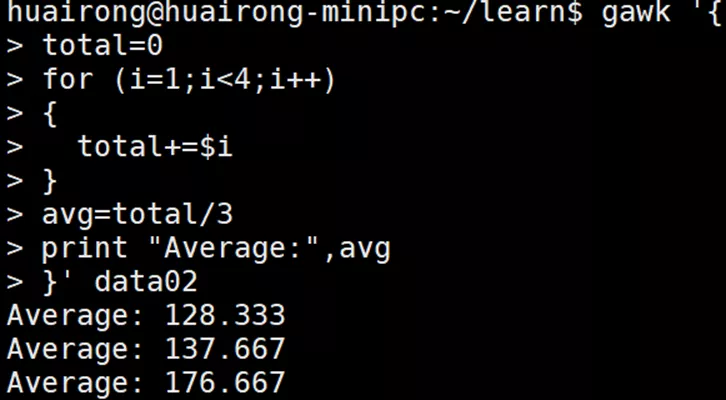
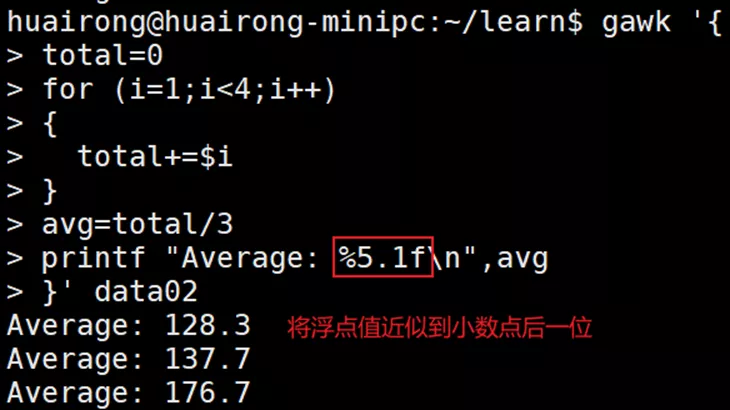
for( variable assignment; condition; iteration process)
5. 格式化打印
- 格式化打印命令:printf
- printf命令的格式:printf "format string", var1, var2…
格式化指定符采用如下格式:
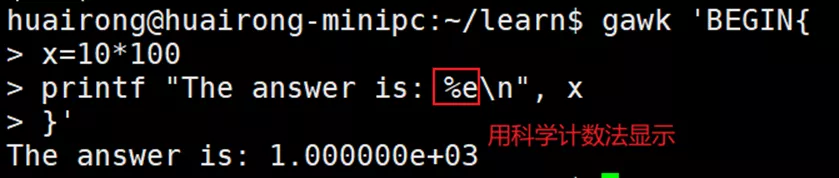
%[modifier]control-letter,control-letter是一个单字符代码,指明显示什么类型的数据,modifier定义了可选的格式化特性。

- width:指定输出字段最小宽度的数字值。如果输出短于width,printf会将文本右对齐,并用空格进行填充。如果输出比width还要长,则按照实际的长度输出。
- prec:数字值,指定浮点数中小数点后面的位数,或者文本字符串中显示的最大字符数。
6. 内建函数
数学函数
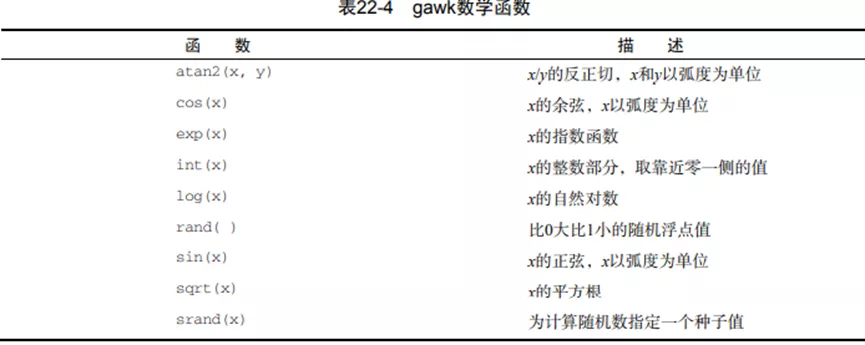
- int():不会取四舍五入进位后的值。
- rand():只创建0和1之间的随机数,不包含0或1。
除标准数学函数外,gawk还支持按位操作数据的函数:
- and(v1, v2):执行值v1和v2的按位与运算。
- compl(val):执行val的补运算。
- lshift(val, count):将值val左移count位。
- or(v1, v2):执行值v1和v2的按位或运算。
- rshift(val, count):将值val右移count位。
- xor(v1, v2):执行值v1和v2的按位异或运算。

字符串函数
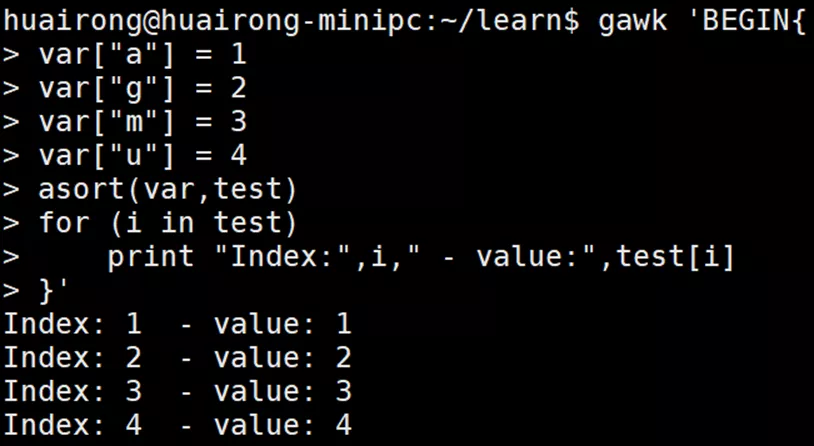
- asort(s [,d]):将数组s按数据元素值排序。索引值会被替换成表示新的排序顺序的连续数字。另外,如果指定了d,则排序后的数组会存储在数组d中。
- asorti(s [,d]):将数组s按索引值排序。生成的数组会将索引值作为数据元素值,用连续数字索引来表明排序顺序。另外如果指定了d,排序后的数组会存储在数组d中。
- gensub(r, s, h [, t]):查找变量$0或目标字符串t(如果提供了的话)来匹配正则表达式r。如果h是一个以g或G开头的字符串,就用s替换掉匹配的文本。如果h是一个数字,它表示要替换掉第h处r匹配的地方。
- gsub(r, s [,t]):查找变量$0或目标字符串t(如果提供了的话)来匹配正则表达式r。如果找到了,就全部替换成字符串s。
- index(s, t):返回字符串t在字符串s中的索引值,如果没找到的话返回0。
- length([s]):返回字符串s的长度;如果没有指定的话,返回$0的长度。
- match(s, r [,a]):返回字符串s中正则表达式r出现位置的索引。如果指定了数组a,它会存储s中匹配正则表达式的那部分。
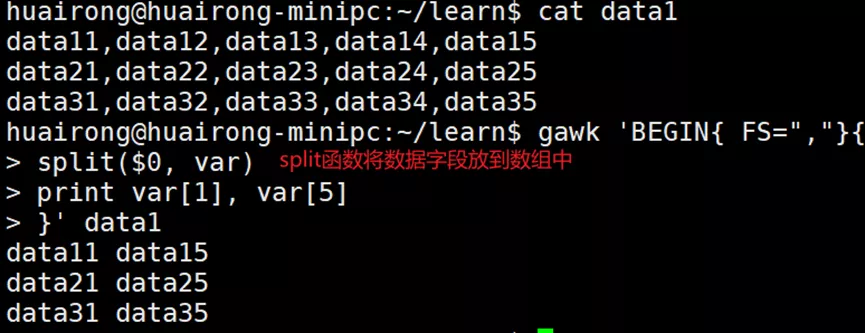
- split(s, a [,r]):将s用FS字符或正则表达式r(如果指定了的话)分开放到数组a中。返回字段的总数。
- sprintf(format, variables):用提供的format和variables返回一个类似于printf输出的字符串。
- sub(r, s [,t]):在变量$0或目标字符串t中查找正则表达式r的匹配。如果找到了,就用字符串s替换掉第一处匹配。
- substr(s, i [,n]):返回s中从索引值i开始的n个字符组成的子字符串。如果未提供n,则返回s剩下的部分。
- tolower(s):将s中的所有字符转换成小写。
- toupper(s):将s中的所有字符转换成大写。

时间函数

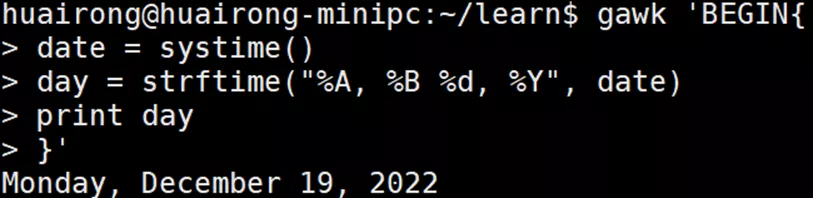
时间函数常用来处理日志文件,而日志文件则常含有需要进行比较的日期。通过将日期的文 本表示形式转换成epoch时间(自1970-01-01 00:00:00 UTC到现在的秒数),可以轻松地比较日期。
下面的例子中用systime函数从系统获取当前的epoch时间戳,然后用strftime函数将它转换成用户可读的格式
7. 自定义函数
定义函数function name([variables])
{
Statements
}
函数名必须能够唯一标识函数。使用自定义函数
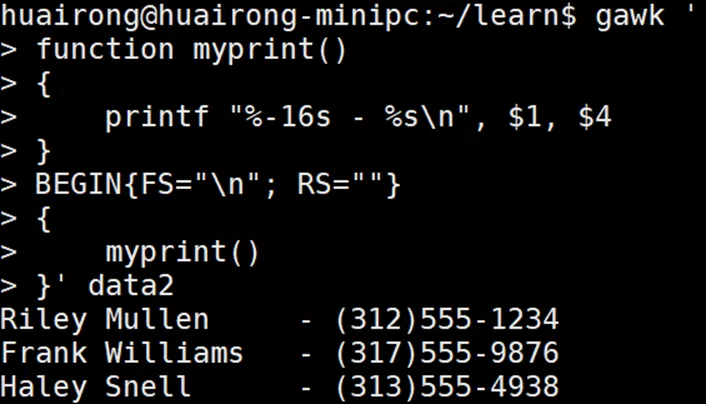
在定义函数时,它必须出现在所有代码块之前(包括BEGIN代码块)。下面的例子中,定义了myprint()函数,它会格式化记录中的第一个和第四个数据字段以供打印输出。
gawk支持将多个函数放到一个文件中,需要使用-f命令行参数来使用它们。但不能将-f命令行参数和内联gawk脚本放到一起使用,不过可以在同一个命令行中使用多个-f参数。
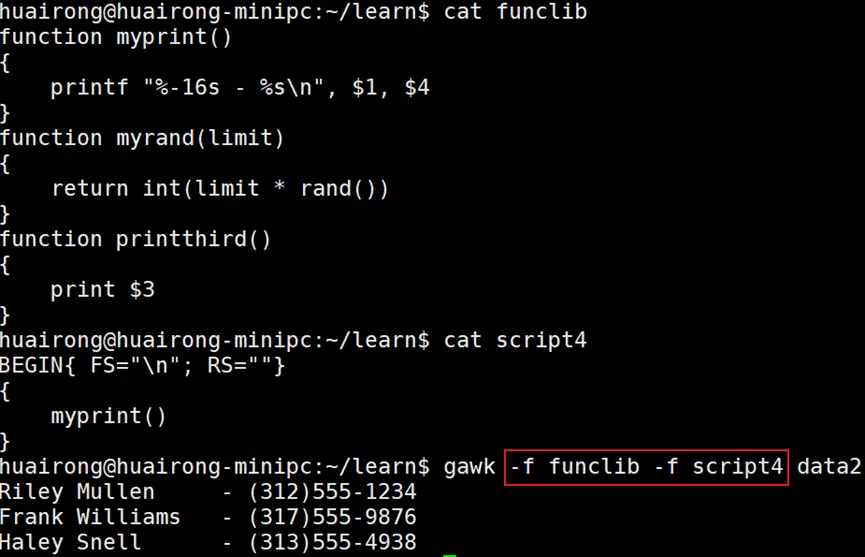
8. 实例
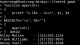
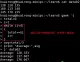
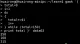
数据文件scores中包含了两支队伍(每队2名选手)的保龄球比赛得分情况,每位选手都有3场比赛的成绩,每位选手由位于第二列的队名来标识。下面的例子对每队的成绩进行了排序,并计算了总分和平均分。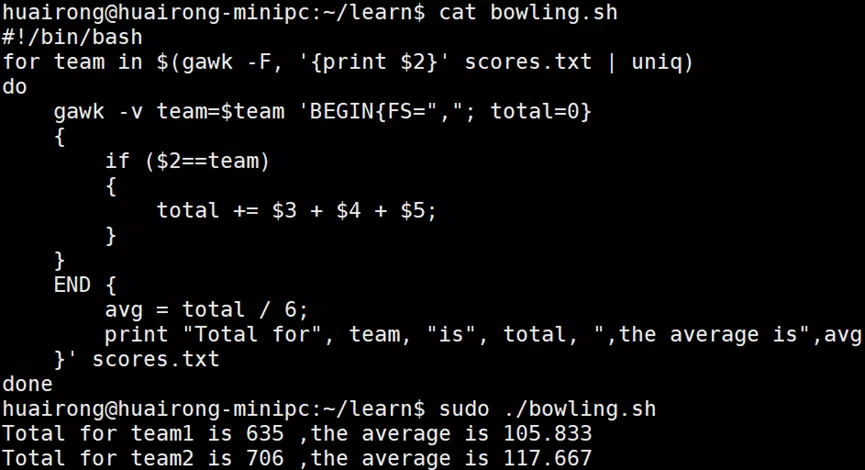
for循环中的第一条语句过滤出数据文件中的队名,然后使用uniq命令返回不重复的队名。 for循环再对每个队进行迭代。
利用gawk的-v选项来确定队名是否和正在进行循环的队名相符,如果队名相符,代码会对数据记录中的三场比赛得分求和,然后将每条记录的值再相加,只要数据记录属于同一队。





























联系我们


刘斌
高级客户经理
电话(微信)
17685869372
QQ号码
526288068
联系邮箱
liubin@chandao.com

完善信息领取项目管理礼包
280+项目管理实践
100+项目管理视频
50+项目管理知识模版
去完善

联系我们


李木
高级客户经理
电话(微信)
18562583552
QQ号码
3985895121
联系邮箱
limu@chandao.com




