做项目管理试题:看国内4家大模型究竟哪家强?(作者:朱少民)
未来,不仅软件研发靠大模型(LLM)驱动,而且项目管理也会靠LLM驱动。暂时就不演练LLM是如何帮忙进行项目管理的,而是先考考它们,看看能否通过考试。如果通过了考试,我们就可以录用它们来参与我们的项目管理。
我选了两组项目管理(偏敏捷研发范式)的试题,一组相对简单的6个试题,找几个人类项目经理(或Scrum Master)来做或讨论,他们的意见比较一致,即缺少争议;另一组题目相对较难的6个试题,人类项目经理做的时候很容易做错,而且大家讨论时,意见也不一致。
然后,我选了国内流行的四大模型的聊天工具:智谱清言、百度文心一言、讯飞星火认知大模型、阿里通义千问,让它们同台竞技。避免影响,在它们竞技完之后,我再构造智能体,将敏捷项目实践、PMBOK等文档作为知识库导入智能体,我还特别特别注意,不导入试题一类的文档,只灌输十个左右的知识文档。
1. 第一组6个较容易的试题,测试四大模型
为了减少篇幅,在这里就不把每个试题的答案都贴出来,每个大模型贴出一个(而且是不同的题目),正好让大家也大致了解6个什么样的试题。
1)智谱回答的第1题,结果正确,而且先给出答案,再做解析,回答规范、清晰。


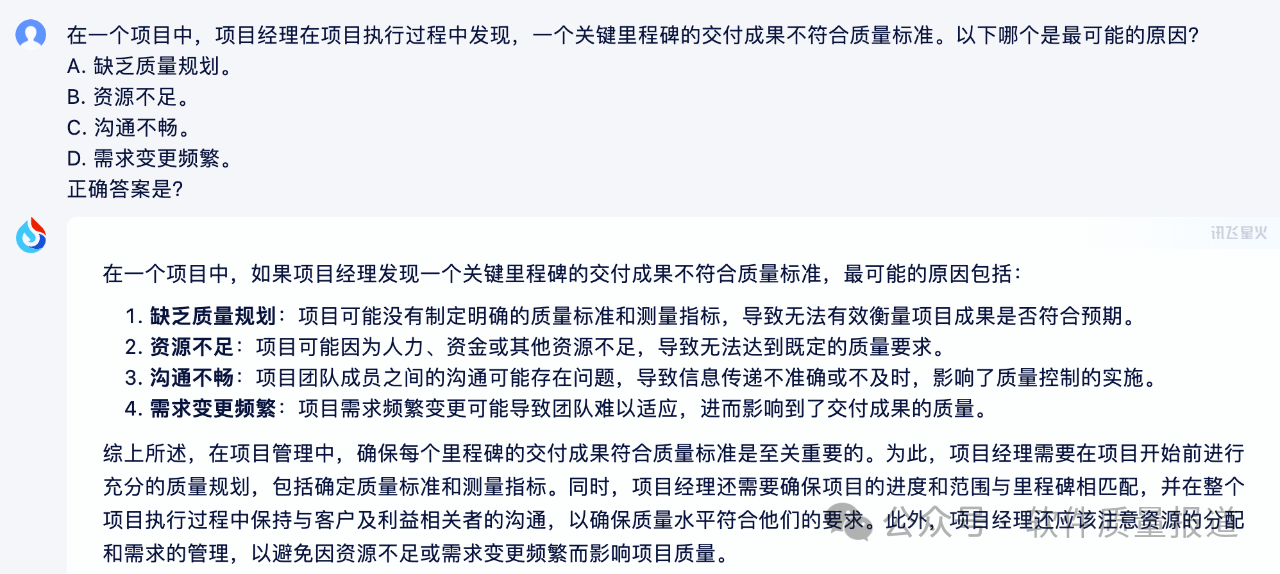
3)讯飞星火回答的第3题,结果正确,但没有给出解析。

回答第4个问题时,没有给出答案(算错),虽然说了一番道理。
4)通义千问回答的第5题,结果正确,也给出了正确的解析,只是回答不够规范。

5)在两组题目都回答之后,我构建了智谱清言智能体“全才项目经理”,它回答的第6题,结果正确,而且之前智谱清言chaGLM回答是错误的:

下面是智谱清言chaGLM回答,答案是错误的,对环境理解不对,这是测试环境,而不是生产环境。

第一组题目做下来,它们的成绩如下,文心一言和智能体得满分,胜出。

2. 第二组6个较难的试题
1)智谱回答的第1题,答案错误,正确答案是C,文心一言和星火答对,而通义千问干脆把A/C都放上(我就算它半对 )。
)。


文心一言正确的回答。

通义千问的半对(机智吗?)回答,A是优先的,错的概率更大。也说明这题的选择是比较困难的。两个模型加上智能体都选A(3:2,错的概率大),题目没出好?

2)文心一言回答的第2题,居然答对了(A),因为另外3个大模型都答错了(都给出B),此处必须给文心一言点赞


错误答案,如通义千问的回答

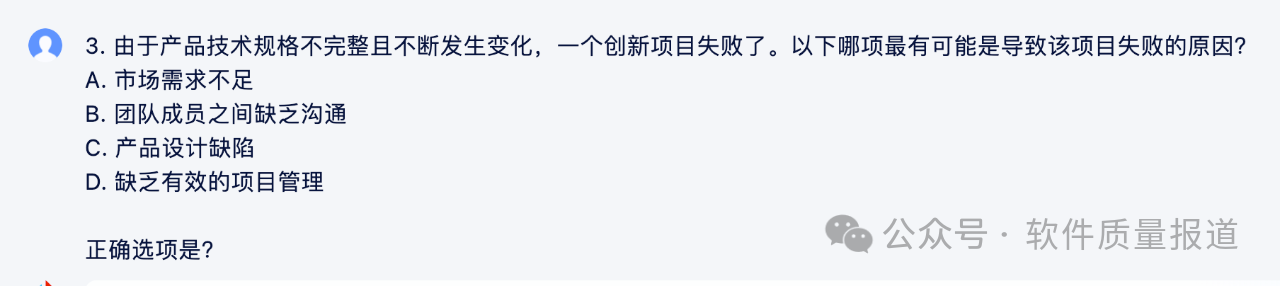
3)讯飞星火和通义千问都答对了第3题(D),也回答得很规范,而另两个模型都答错了(C)。

那么看看智谱清言是怎么错误理解的?

4)通义千问和智谱清言都答对了第4题(D),而另两个模型都答错了(A)。


那么看看文心一言是怎么答错的?

5)第5题可能比较简单(智谱清言都懒得做解析 ),4大模型都答对了(B)。
),4大模型都答对了(B)。


6)第6题可能很难,4大模型都答错了(C),只有智能体答对了(B)。

错误的理解是这样的:

第二组测试的结果:四大模型都没有及格(低于60分),智谱清言分数最低,只答对1/3,其它三个模型不分伯仲。但智能体优势明显,答对5题,得了83.33分。

测试的最后结果出来了
第1名:智能体: 11/12= 91.67分
第2名:文心一言: 9/12 = 75
第3名:通义千问: 7.5/12 =62.5
第4名:讯飞星火: 7/12= 58.3(那两题没给出答案,算它错,so 排在前面)
第5名:智谱清言: 7/12 = 58.3
大家有何看法或评论,欢迎留言。
本文转载自【软件质量报道】公众号
原文作者:朱少民




感谢您的!为确保您能充分发挥禅道的价值,我们为您准备了以下专属服务:
 精品资料包
精品资料包立即获取《软件研发质量管理体系建设白皮书》、《PMO实践白皮书》《IPD资料》等行业最佳实践资料。
 1V1产品演示
1V1产品演示为您量身定制线上演示,深度讲解核心功能与适用场景。
 免费试用增强功能
免费试用增强功能获取正式试用授权,解锁全部功能,带领团队亲身体验。
 专属顾问答疑支持
专属顾问答疑支持在使用中遇到的任何问题,您的专属顾问将及时为您解答。
添加您的专属顾问获取服务

扫码添加领专属服务


