用 PHP 处理 10 亿行数据!(作者:校长)
当然,这个事情是根据GitHub上的一个“十亿行挑战”(1brc)活动而来,现在正在进行,如果你没有听说过,可查看Gunnar Morlings 的 1brc 存储库。https://github.com/gunnarmorling/1brc
我之所以被吸引,是因为社区中的两位同事参加了比赛。以下地址是全球各地开发者的代码排行榜。
https://github.com/gunnarmorling/1brc?tab=readme-ov-file#results
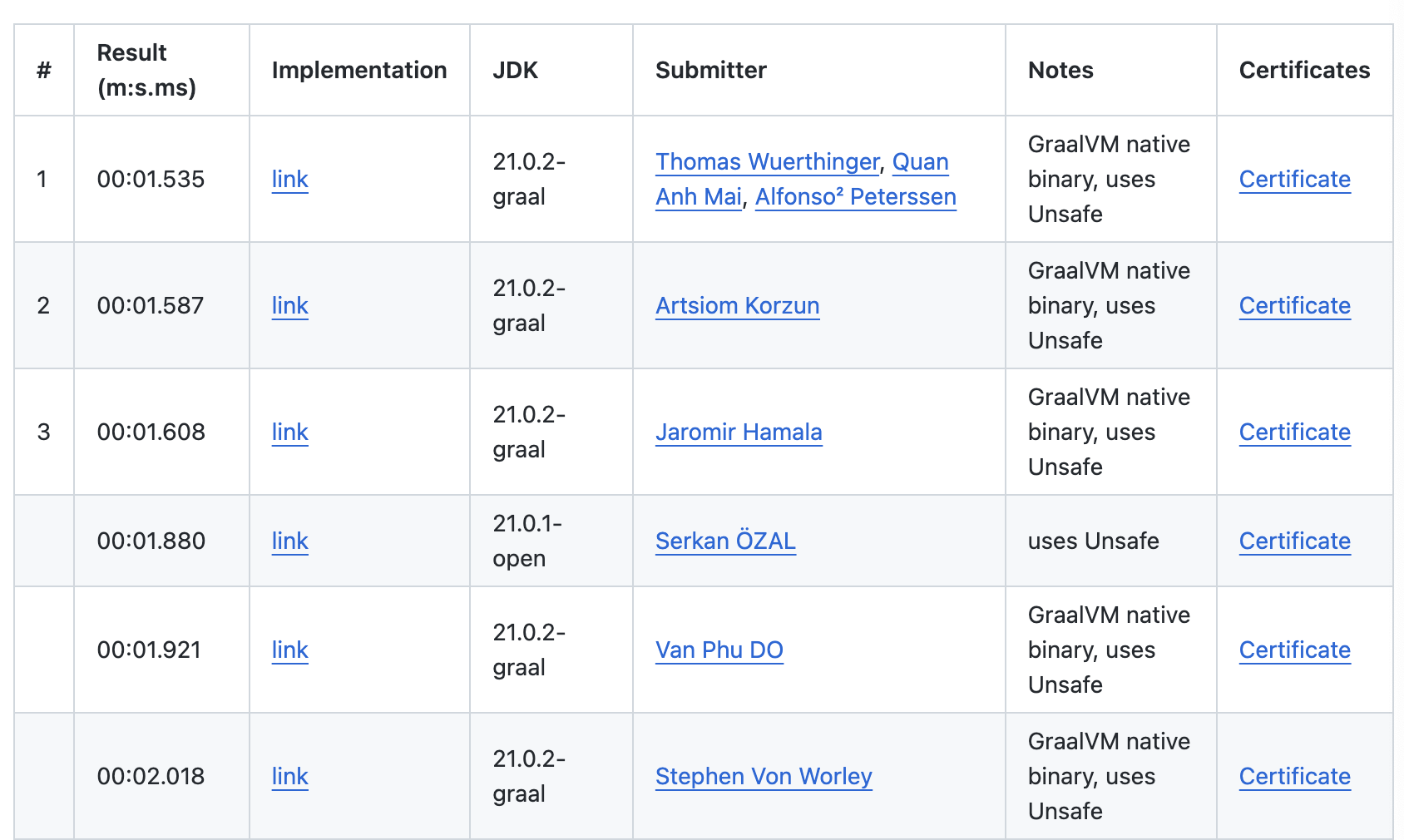
图1 10亿行代码处理速度排行榜
我只截图一小部分,感兴趣的朋友还可以浏览上面的网址。
使用PHP加入速度排行榜
大家知道,PHP 并不以速度最快而闻名。在我开发 PHP 分析器时,我想应该尝试一下它,看看能达到多快的速度。第一种,最“幼稚”的方法
我克隆了存储库,下载了measurements.txt(一个csv格式文件)后,我开始构建第一个最“天真纯朴”的实现,但是能够解决这个挑战。代码如下:
<?php
$stations = [];
$fp = fopen('measurements.txt', 'r');
while ($data = fgetcsv($fp, null, ';')) {
if (!isset($stations[$data[0]])) {
$stations[$data[0]] = [
$data[1],
$data[1],
$data[1],
1
];
} else {
$stations[$data[0]][3] ++;
$stations[$data[0]][2] += $data[1];
if ($data[1] < $stations[$data[0]][0]) {
$stations[$data[0]][0] = $data[1];
}
if ($data[1] > $stations[$data[0]][1]) {
$stations[$data[0]][1] = $data[1];
}
}
}
ksort($stations);
echo '{';
foreach($stations as $k=>&$station) {
$station[2] = $station[2]/$station[3];
echo $k, '=', $station[0], '/', $station[2], '/', $station[1], ', ';
}
echo '}';这里没什么可炫耀的,我们先打开文件,然后用来fgetcsv()函数来读取数据。如果未找到元素,则创建新的空的stations数组和相应列,如要有数据则增加计数,对温度求和,并查看当前温度是否低于或高于最小值或最大值,并做相应的更新。我把所有东西都放在一起,使用ksort()按$stations数组顺序排列,然后回显数组并计算平均温度(总和/计数)。
简单描述完算法,然后在我的笔记本电脑上运行了这个简单代码,它需要25 分钟。
就想着如何优化,下面查看分析器运行结果:
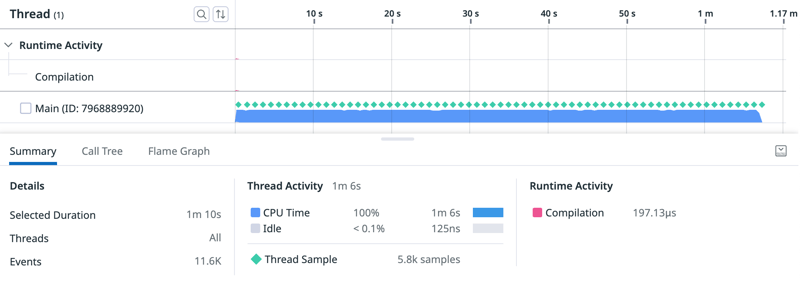
可视化的时间轴帮助我看到了,明显是 CPU 限制了速度,脚本开头的文件编译可以忽略不计,并且也没有垃圾收集事件。
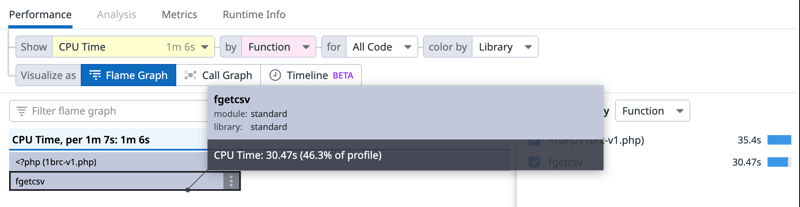
使用fgets()代替fgetcsv()
第一个优化是使用fgets()手动获取每一行,然后根据文件;分号分割,而不在依赖fgetcsv()。这主要是因为我看 fgetcsv()所做的远远超出了本人的“预期”图片。更换后的主要代码如下:// ...
while ($data = fgets($fp, 999)) {
$pos = strpos($data, ';');
$city = substr($data, 0, $pos);
$temp = substr($data, $pos+1, -1);
// ...此外,我还$data[0]以及各个数组进行了重构。通过这一更改,再次运行脚本就已将运行时间降至19m 49s。从绝对数字来看,下降了很多,是 21%!
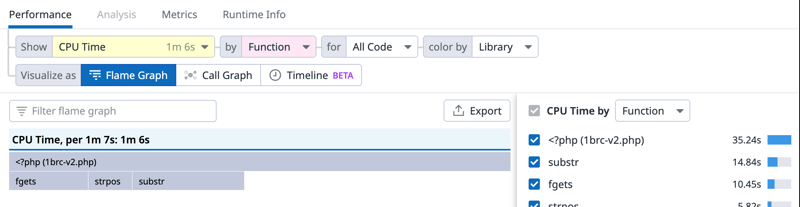
火焰图也反映了这一变化,切换到按行显示, CPU 时间也提示了中间发生的情况:
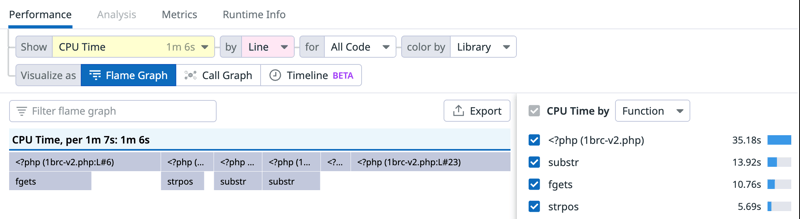
我又发现在第 18 行和第 23 行花费了约 38% 的 CPU 时间,它们是:
18 | $stations[$city][3] ++;
| // ...
23 | if ($temp > $stations[$city][1]) {第 18 行是循环中对数组$stations的第一次访问,它做了一个自增,第 23 行是一个比较,乍一看似乎没有怎么花费时间,让我们对它再做一些优化,会看到这里花费了时间。首先,要尽可能地使用“引用操作符”—&:
$station = &$stations[$city]; $station[3] ++; $station[2] += $temp; // instead of $stations[$city][3] ++; $stations[$city][2] += $data[1];
这样应该有助于 PHP 在每次访问数组时不必搜索数组$stations中的键,将其视为用于访问数组中“当前”的缓存。实际上它也非常有帮助,此次运行只需要17m 48s,又减少了 10%!
只包含一处比较
在查看代码时,我偶然发现了以下这段代码:if ($temp < $station[0]) {
$station[0] = $temp;
}
if ($temp > $station[1]) {
$station[1] = $temp;
}新版本的代码执行时间为 17m 30s,又增加了约 2%。添加类型转换
PHP被认为是一种动态语言,这是我刚开始编写软件时非常看重的东西,少了一些需要关心的问题。但另一方面,了解类型有助于引擎在运行代码时做出更好的决策。下列代码来看一下:
$temp = (float)substr($data, $pos+1, -1);
你猜怎么着?这个简单的转换,让脚本运行时间仅为13m 32s,性能提升了 21%!
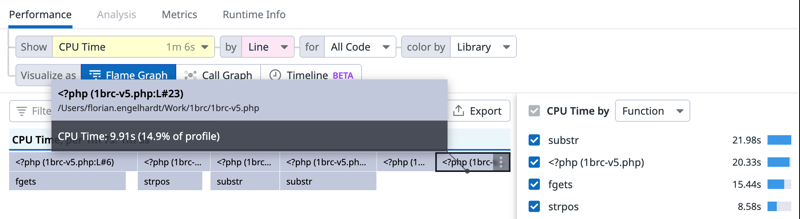
18 | $station = &$stations[$city];
| // ...
23 | } elseif ($temp > $station[1]) {第 18 行仍然显示出 11% 的 CPU 时间消耗,这是对数组的访问(在哈希映射中查找键,哈希映射(HashMap)是 PHP 中用于关联数组的底层数据结构)。第 23 行修改后 CPU 时间从 ~32% 下降到 ~15%。这是因为 PHP 不再进行类型转换处理。使用 JIT 怎么样?
PHP 中的 OPCache 在 CLI 状态中默认处于禁用状态,需要将opcache.enable_cli设置设置为on。
JIT(作为 OPCache 的一部分)默认启用,但由于缓冲区大小设置为0,因此相当于有效禁用,因此我设置了opcache.jit-buffer-size项,例如使用10M。应用这些更改后,我使用 JIT 重新运行脚本并看到它完成:7m 19s !花费的时间减少了45.9%!
还有什么!?
现在,我已经将运行时间从一开始的 25 分钟缩短到了大约 7 分钟。
我还发现令人惊讶的一件事是fgets()分配 56 GiB/m 的内在来读取 13 GB 文件。好像有些不太对劲,所以我又检查了fgets()的实现,看起来我可以通过省略参数来节省大量长度比较,再分配fgets():
while ($data = fgets($fp)) {
// instead of
while ($data = fgets($fp, 999)) {比较更改前后的配置文件可以得出以下结果: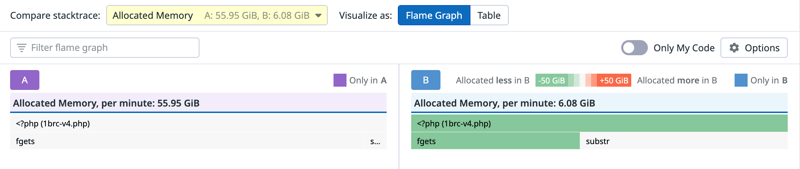
你可能认为这次又带来了很大的性能提升,但实际上只有大约 1%。这是因为这些是Zend内存管理器可以在处理的更小的二进制分配,但是它的速度非常快。
可以让它更快吗?
是的,我们可以!到目前为止,我的方法还是单线程,这是大多数 PHP 软件的本质,但 PHP 确实通过并行扩展支持用户态中的线程。
<?php
$file = 'measurements.txt';
$threads_cnt = 16;
/**
* Get the chunks that each thread needs to process with start and end position.
* These positions are aligned to \n chars because we use `fgets()` to read
* which itself reads till a \n character.
*
* @return array<int, array{0: int, 1: int}>
*/
function get_file_chunks(string $file, int $cpu_count): array {
$size = filesize($file);
if ($cpu_count == 1) {
$chunk_size = $size;
} else {
$chunk_size = (int) ($size / $cpu_count);
}
$fp = fopen($file, 'rb');
$chunks = [];
$chunk_start = 0;
while ($chunk_start < $size) {
$chunk_end = min($size, $chunk_start + $chunk_size);
if ($chunk_end < $size) {
fseek($fp, $chunk_end);
fgets($fp); // moves fp to next \n char
$chunk_end = ftell($fp);
}
$chunks[] = [
$chunk_start,
$chunk_end
];
$chunk_start = $chunk_end+1;
}
fclose($fp);
return $chunks;
}
/**
* This function will open the file passed in `$file` and read and process the
* data from `$chunk_start` to `$chunk_end`.
*
* The returned array has the name of the city as the key and an array as the
* value, containing the min temp in key 0, the max temp in key 1, the sum of
* all temperatures in key 2 and count of temperatures in key 3.
*
* @return array<string, array{0: float, 1: float, 2: float, 3: int}>
*/
$process_chunk = function (string $file, int $chunk_start, int $chunk_end): array {
$stations = [];
$fp = fopen($file, 'rb');
fseek($fp, $chunk_start);
while ($data = fgets($fp)) {
$chunk_start += strlen($data);
if ($chunk_start > $chunk_end) {
break;
}
$pos2 = strpos($data, ';');
$city = substr($data, 0, $pos2);
$temp = (float)substr($data, $pos2+1, -1);
if (isset($stations[$city])) {
$station = &$stations[$city];
$station[3] ++;
$station[2] += $temp;
if ($temp < $station[0]) {
$station[0] = $temp;
} elseif ($temp > $station[1]) {
$station[1] = $temp;
}
} else {
$stations[$city] = [
$temp,
$temp,
$temp,
1
];
}
}
return $stations;
};
$chunks = get_file_chunks($file, $threads_cnt);
$futures = [];
for ($i = 0; $i < $threads_cnt; $i++) {
$runtime = new \parallel\Runtime();
$futures[$i] = $runtime->run(
$process_chunk,
[
$file,
$chunks[$i][0],
$chunks[$i][1]
]
);
}
$results = [];
for ($i = 0; $i < $threads_cnt; $i++) {
// `value()` blocks until a result is available, so the main thread waits
// for the thread to finish
$chunk_result = $futures[$i]->value();
foreach ($chunk_result as $city => $measurement) {
if (isset($results[$city])) {
$result = &$results[$city];
$result[2] += $measurement[2];
$result[3] += $measurement[3];
if ($measurement[0] < $result[0]) {
$result[0] = $measurement[0];
}
if ($measurement[1] < $result[1]) {
$result[1] = $measurement[1];
}
} else {
$results[$city] = $measurement;
}
}
}
ksort($results);
echo '{', PHP_EOL;
foreach($results as $k=>&$station) {
echo "\t", $k, '=', $station[0], '/', ($station[2]/$station[3]), '/', $station[1], ',', PHP_EOL;
}
echo '}', PHP_EOL;首先我扫描文件并将其分割成以\n对齐的块,我稍后会使用fgets()函数。当准备好块时,我启动$threads_cnt工作线程,然后所有线程都打开同一个文件并寻找分配的块,开始并读取和处理数据直到块结束,返回一个中间结果,然后主线程将其组合、排序并打印出来。这种多线程方法只需:1 分 35 秒!
这就是结局?
当然不是。这个解决方案至少还有两件事要做:- 我在 Apple Silicon 硬件上的 MacOS 上运行此代码,在 PHP 的 ZTS 版本中使用 JIT 时会崩溃,因此 1m 35s 结果是没有使用上 JIT 的,如果我可以使用它,它可能会更快;
- 我意识到我正在运行一个 PHP 版本,该版本是CFLAGS="-g -O0 ..."根据我日常工作的需要而自定义编译的。
我应该在一开始就检查一下这一块,所以我重新编译了 PHP 8.3,并修改了参数CLFAGS="-Os ..."。于是我的最终数字(16 个线程处理)是:27.7 秒!
这是一个有 10 个线程的时间线视图:
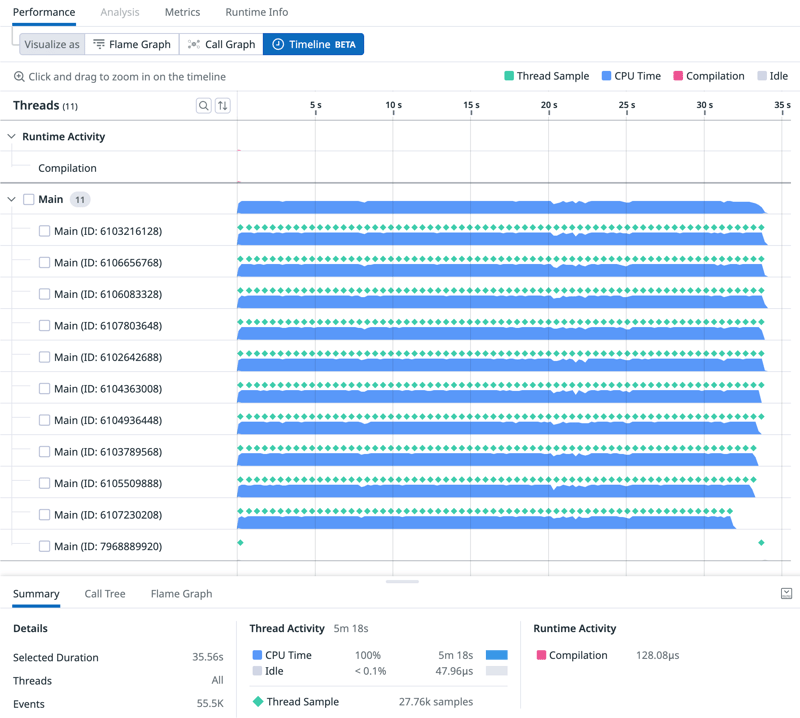
最底层的线程是主线程,等待工作线程的结果。一旦这些worker返回了中间结果,就可以看到主线程正在对所有内容进行组合和排序。我们也可以清楚地看到,主线程不再是瓶颈。
我在路上学到了什么?
每个抽象层只是用可用性/集成来换取 CPU 周期或内存。fgetcsv()虽然超级易用,但隐藏了很多东西,这是有代价的。虽然fgets()也向我们隐藏了一些东西,但它让读取数据变得更灵活和方便。
在代码中添加类型,将有助于语言优化执行或停止类型转换(这是我们看不到的东西,但是需要付出 CPU 周期的代价)。
原文作者:校长
原文链接:https://mp.weixin.qq.com/s/mctgCCPqjQl0OKe0AtwXpw
声明:版权属于原文作者,如有侵权,请联系删除。
 麦大穗
麦大穗 禅道-Bee
禅道-Bee




感谢您的!为确保您能充分发挥禅道的价值,我们为您准备了以下专属服务:
 精品资料包
精品资料包立即获取《软件研发质量管理体系建设白皮书》、《PMO实践白皮书》《IPD资料》等行业最佳实践资料。
 1V1产品演示
1V1产品演示为您量身定制线上演示,深度讲解核心功能与适用场景。
 免费试用增强功能
免费试用增强功能获取正式试用授权,解锁全部功能,带领团队亲身体验。
 专属顾问答疑支持
专属顾问答疑支持在使用中遇到的任何问题,您的专属顾问将及时为您解答。
添加您的专属顾问获取服务

扫码添加领专属服务


