87066
我想爬虫爬取特定的标题的bug,我想模拟禅道自带的自定义搜索功能来获取其页面,然后再提取其页面中的信息(python爬虫)
回帖数 6
阅读数 4344
发表时间 2017-08-28 15:36:55
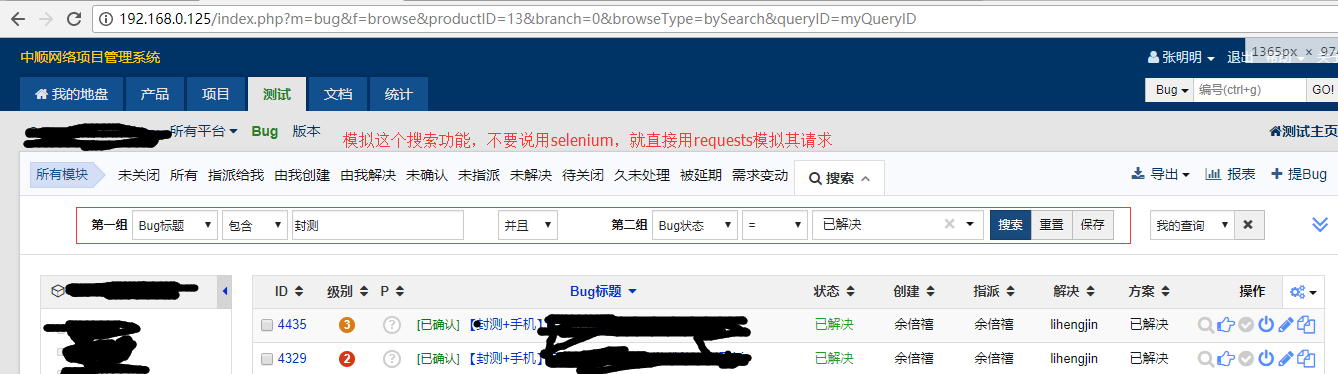
 刷新一次网页,产生了3个http请求,请求之间都是相互依赖的,求大神指点迷津
刷新一次网页,产生了3个http请求,请求之间都是相互依赖的,求大神指点迷津  石洋洋
石洋洋 6个回复
原帖由 石洋洋 于 2020-09-22 13:47:56 发表
@ 廖荣玄:没有session是模拟不了的。
那我如果用session,session不进行重新更换,就每次结果都会一致么?
那您这边知道python有什么更换session的方式么?或者说清楚之前session中的内容
2020-09-24 17:13:15 廖荣玄 回帖
6个回复
是的,session一样的话结果是一样的。
python这块我们没有用过不太熟悉,可能帮不太上什么忙,需要您再研究一下了。
建议您可以试试直接通过mysql进行搜索获取数据呢
2020-09-24 17:40:39 王林 回帖
联系我们

联系人
刘璐/高级客户经理
电话(微信)
18562550650
QQ号码
2845263372
联系邮箱
liulu@chandao.com

相关帖子
董震 | 最后回帖 2017-06-20 08:29 王春生
speed | 最后回帖 2016-08-29 14:11 石洋洋
阿西巴 | 最后回帖 2016-03-25 20:36 lifei
名义 | 最后回帖 2021-08-24 12:34 微微
贾明 | 最后回帖 2023-11-16 09:30 禅道-阿龙
li yun tao li | 最后回帖 2018-09-30 10:12 石洋洋
联系我们
刘璐
高级客户经理
电话(微信)
18562550650
QQ号码
2845263372
联系邮箱
liulu@chandao.com
联系我们


李木
高级客户经理
电话(微信)
18562583552
QQ号码
3985895121
联系邮箱
limu@chandao.com
!您的禅道专属服务通道已开启
感谢您的!为确保您能充分发挥禅道的价值,我们为您准备了以下专属服务:
 精品资料包
精品资料包立即获取《软件研发质量管理体系建设白皮书》、《PMO实践白皮书》《IPD资料》等行业最佳实践资料。
 1V1产品演示
1V1产品演示为您量身定制线上演示,深度讲解核心功能与适用场景。
 免费试用增强功能
免费试用增强功能获取正式试用授权,解锁全部功能,带领团队亲身体验。
 专属顾问答疑支持
专属顾问答疑支持在使用中遇到的任何问题,您的专属顾问将及时为您解答。
添加您的专属顾问获取服务

扫码添加领专属服务


